k8s HA 구성과 kubespray를 통한 클러스터 배포
지난 학습 자료를 통해 도커와 쿠버네티스, 그리고 관리형 쿠버네티스 서비스인 AWS EKS 등에 대해 알아보았습니다. 또 업로드해드린 자료를 통해 직접 쿠버네티스 클러스터를 구성해보신 분들도 계셨는데요. 지난 자료에 업로드해드린 쿠버네티스 클러스터는 모두 클러스터를 생성하는 가장 기본적인 방법인 kubeadm을 통한 방법이었습니다. 아래는 쿠버네티스의 컴포넌트 구성도인데요. 기억이 나실지 모르겠습니다.
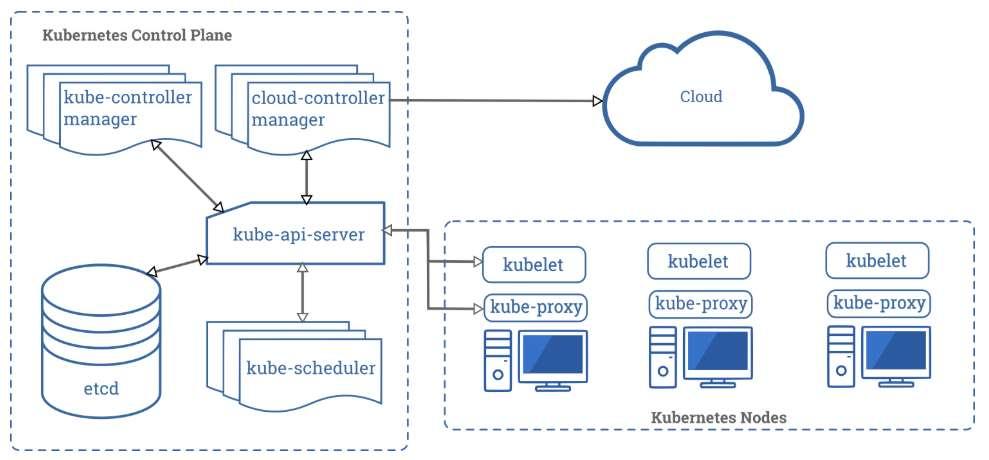
이 구성도에서는 하나의 마스터노드와 3개의 워커노드로 구성된 클러스터의 모습 보여주고 있는데요. (현재는 마스터노드/워커노드라는 용어보다 컨트롤플레인/데이터플레인이라는 용어를 사용하는데, 마스터노드/워커노드라는 용어가 더 직관적이라고 생각해서 용어는 그대로 통일해서 마스터노드/워커노드로 표현하겠습니다)
하지만 실제 프로덕션 환경에서는 워커노드와의 api 통신을 위한 kube-apiserver, 클러스터의 모든 정보를 저장하는 키값저장소인 etcd를 하나의 마스터노드로만 운영하기에는 부하 분산 및 장애 대비 측면에서 부족할 수 있습니다. 때문에 개발환경이 아닌 프로덕션 환경이라면 마스터노드(kube-apiserver, etcd)는 HA구성을 고려할 필요가 있는데요.
이번 글에서는 쿠버네티스, 특히 마스터노드의 HA 구성을 알아보고, HA 구성을 포함한 쿠버네티스 클러스터를 빠르고 쉽게 배포할 수 있게 해주는 도구인 kubespray를 통해 배포하는 실습까지 진행해보겠습니다. (발췌한 구성도 및 자료는 쿠버네티스 공식 문서(https://kubernetes.io/ko/docs/home/)를 인용한 점 알려드립니다)
쿠버네티스 공식 문서에서는 클러스터의 HA 구성을 위해 아래와 같은 두 가지 옵션을 안내하고 있습니다.
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/ha-topology/
stacked etcd
아래 그림은 외부 로드밸런서를 통해 다중화된 마스터노드의 구성을 보여줍니다.
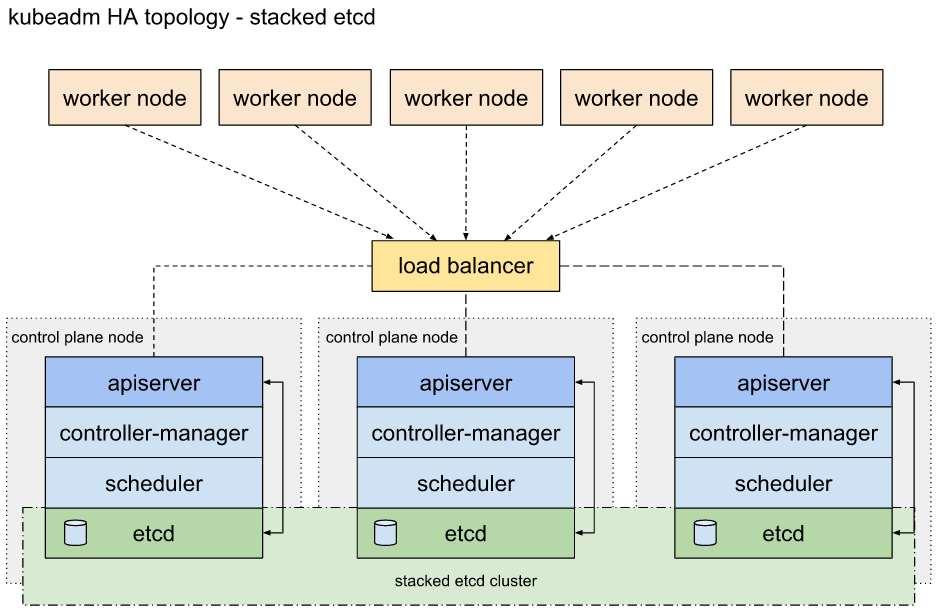
또한 etcd는 마스터노드에 포함되어 있기 때문에 마스터노드의 수 만큼 etcd의 수도 중첩되어(stacked) 구성된 모습입니다. 마스터노드에 etcd가 포함된 stacked etcd 구성은 etcd 클러스터를 외부에 구축한 2번 옵션인 external etcd 구성에 비교하여 아래와 같은 특징을 가집니다.
1) 마스터노드에 etcd 가 포함되어 있기 때문에 구성이 간편함
2) 마스터노드의 수가 늘어남에 따라 etcd의 수도 늘어남
3) 마스터노드에 etcd 가 포함되어 있기 때문에 마스터노드(kube-apiserver) 부하 발생 시 etcd에도 영향을 미침
4) 마스터노드에 etcd 가 포함되어 있기 때문에 RAFT 알고리즘의 정상적인 작동을 위해서는 마스터노드를 홀수로 구성해야함(RAFT 알고리즘이란 리더와 팔로워의 관계를 통해 다중화된 데이터의 정확성을 높이는 방식으로 redis, etcd에서 사용하는 방식입니다. RAFT 알고리즘에 대해 더 이해하시고자하는 경우 http://thesecretlivesofdata.com/raft/ 페이지 방문하시어 예제를 통해 확인하시는 것을 권장드립니다)external etcd
아래는 외부에 etcd 클러스터를 별도로 구축하고 마스터노드는 kube-apiserver를 비롯한 컨트롤러, 스케줄러의 역할만 수행하도록 구성하는 방식을 보여줍니다.
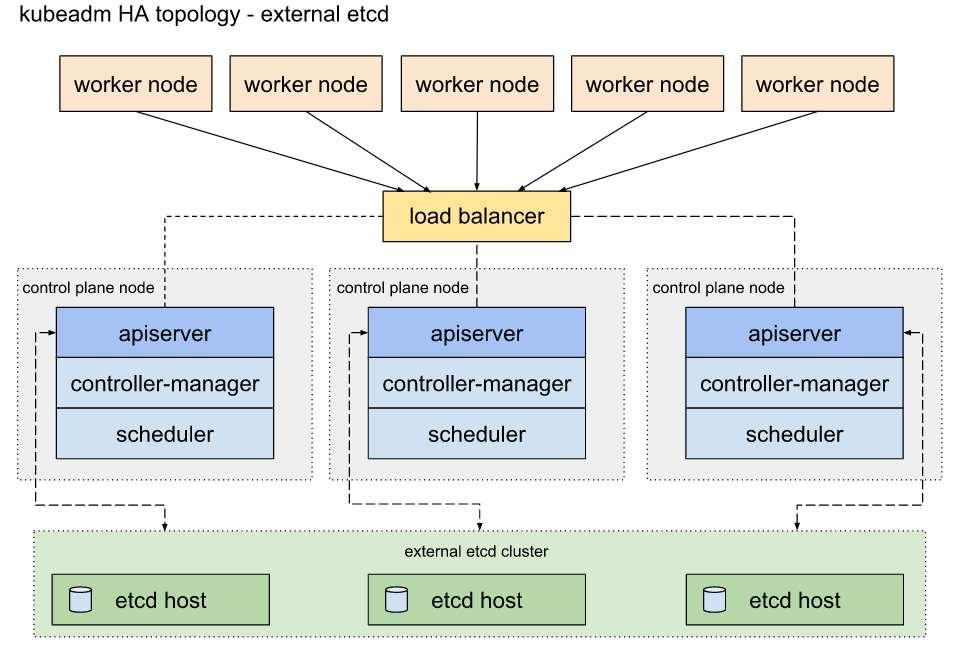
external etcd 방식은 기존 stacked etcd 방식의 HA 구성에 비교하여 etcd 가 외부에 있기 때문에 위 구성은 아래와 같은 특징을 가집니다.
1) etcd 클러스터를 외부에 구성하기 때문에 stacked etcd 구성에 비해 더 많은 수의 노드가 필요함
2) 마스터노드(kube-apiserver)와 etcd의 수를 별도로 구성 가능하며, 마스터노드에 etcd 가 없기 때문에 마스터노드를 짝수로도 구성 가능함
3) etcd 가 외부에 있기 때문에 마스터노드(kube-apiserver)에 부하가 발생하여도 stacked etcd 구성에 비해 etcd에 미치는 영향도가 적음쿠버네티스 클러스터를 고가용성으로 구성하는 두 가지 옵션에 대해 설명해드렸는데요. 우리는 이러한 HA 구성이 포함된 쿠버네티스 클러스터를 쉽게 배포할 수 있는 도구인 kubespray를 통해 쿠버네티스 클러스터를 배포해볼 것입니다. 구성할 클러스터의 HA 옵션은 2번 옵션인 external etcd 로 구성할 예정입니다. (stacked etcd 구성에 비해 상대적으로 복잡한 구성인 external etcd로 구성하는 것으로 어떤 HA 구성이 더 낫다는 것은 아닙니다. 구성한 환경 및 목적에 맞는 HA 구성이 올바른 구성인 점 안내드립니다.)
이제 실습에 들어갑니다. 아래부터 실습 진행입니다.
구성할 환경
먼저 구성할 쿠버네티스 클러스터 환경을 소개해드리겠습니다.
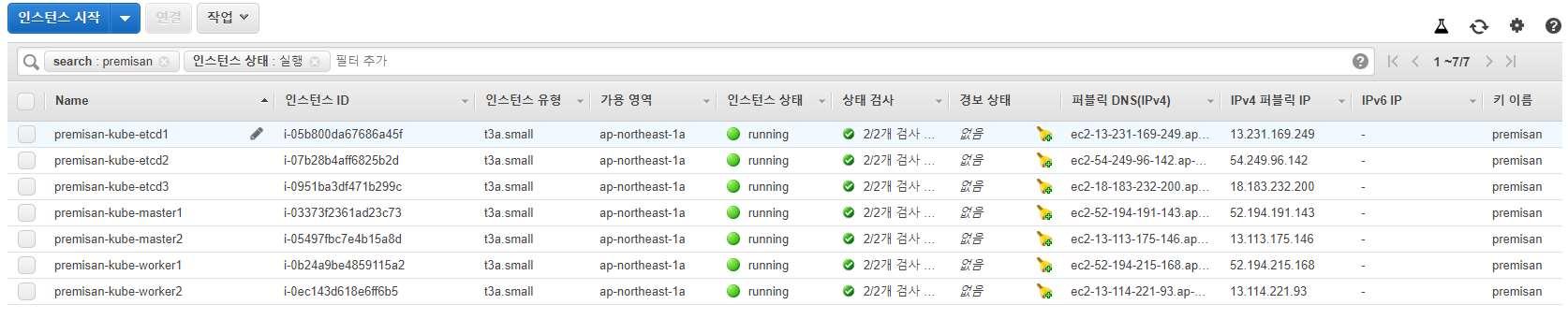
노드에 사용할 자원 - AWS EC2
마스터노드(kube-apiserver) - 2개
etcd 노드 - 3개(etcd는 반드시 홀수로 구성해야합니다)
워커노드 - 2개생성한 인스턴스의 모습은 아래와 같습니다.
인스턴스 생성 시 아래와 같이 사용자 데이터 설정했습니다. 필수적인 것은 아니지만 설정해줘도 좋습니다.
#!/bin/bash
exec > >(tee /var/log/user-data.log|logger -t user-data -s 2>/dev/console) 2>&1
echo "########## user-data start ##########"
timedatectl set-timezone Asia/Seoul && date
echo "export HISTTIMEFORMAT=\"%F %T \"" >> /etc/profile
source /etc/profile
cat << EOF >> /etc/sysctl.conf
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_retries1 = 2
net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.conf.all.rp_filter = 1
net.ipv4.conf.default.rp_filter = 1
EOF
sysctl -p
cat << EOF >> /etc/crontab
#DATE sync
0 0 * * * /usr/bin/rdate -s time.bora.net && /sbin/clock -w
EOF
systemctl restart crond && cat /etc/crontab
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
sestatus
PING=1
until [ $PING == 0 ]; do ping 8.8.8.8 -c1; PING=`echo $?`; done;
yum install -y epel-release rdate vim
yum update -y
yum groupinstall -y 'Development Tools'
echo "########## user-data end ##########"보안그룹은 사무실 공인 아이피와 쿠버네티스 노드로 사용할 인스턴스가 포함된 보안그룹끼리는 모든 트래픽을 오픈하였습니다.
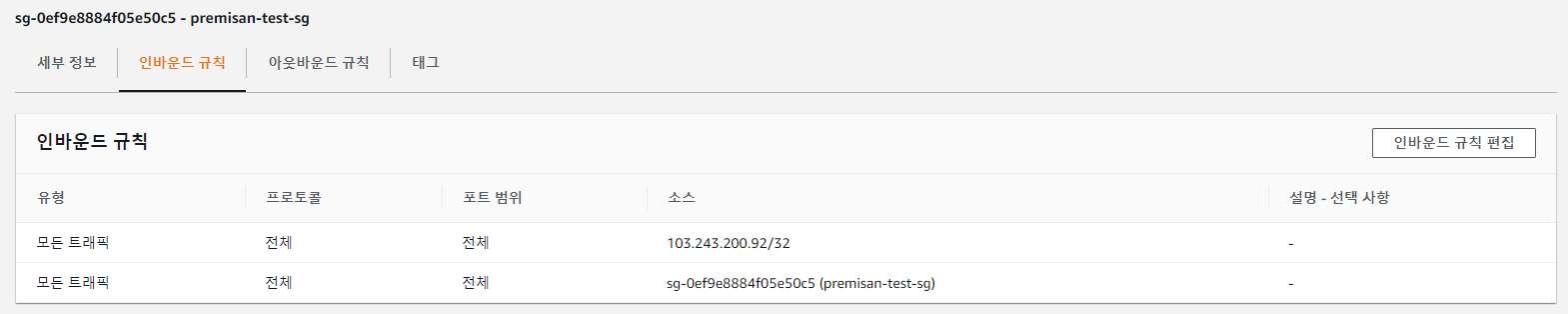
디테일하게 보안그룹을 설명해보시고 싶으신 분은 아래 쿠버네티스 클러스터의 노드 별 포트 정보를 확인하시어 구성해보시기 바랍니다.
(참고) 마스터 노드에 필요한 포트
6443 포트 : Kubernetes API Server / Used By All
2379~2380 포트 : etcd server client API / Used By kube-apiserver, etcd
10250 포트 : Kubelet API / Used By Self, Control plane
10251 포트 : kube-scheduler / Used By Self
10252 포트 : kube-controller-manager / Used By Self(참고) 워커 노드에 필요한 포트
10250 포트 : Kubelet API / Used By Self, Control plane
30000~32767 포트 : NodePort Services / Used By All사전작업(모든 노드)
구성에 사용할 7대 노드에 SSH를 통해 접속하여 아래와 같이 사전 설정 진행합니다.
# swapoff(모든 노드)
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
swapoff -a# disable selinux(모든 노드)
setenforce 0
sed -i s/SELINUX=enforcing/SELINUX=disabled/ /etc/selinux/config# edit kernel parameter(모든 노드)
lsmod | grep br_netfilter
modprobe br_netfilter
cat << EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system아래부터는 kubesparay를 설치 및 실행할 1개의 노드에서 진행합니다.
환경변수 세팅
위에서부터 순서대로 마스터노드 2개, 워커노드 2개, etcd 노드 3개의 아이피주소입니다.
export HOST0=172.16.0.248
export HOST1=172.16.0.175
export HOST2=172.16.0.207
export HOST3=172.16.0.48
export HOST4=172.16.0.219
export HOST5=172.16.0.111
export HOST6=172.16.0.93
export HOSTS="${HOST0} ${HOST1} ${HOST2} ${HOST3} ${HOST4} ${HOST5} ${HOST6}"/etc/hosts 파일에 노드 정보 추가
쉽게 각 노드로 접근하기 위해 아래와 같이 호스트 파일 수정해줍니다.
cat << EOF >> /etc/hosts
${HOST0} premisan-kube-master1
${HOST1} premisan-kube-master2
${HOST2} premisan-kube-worker1
${HOST3} premisan-kube-worker2
${HOST4} premisan-kube-etcd1
${HOST5} premisan-kube-etcd2
${HOST6} premisan-kube-etcd3
EOF(참고로, AWS 리소스를 연동하여 사용하기 위해 클라우드 공급자(cloud provider) 옵션을 추가적으로 설정하여 클러스터를 구성하려는 경우 호스트 명은 반드시 EC2 인스턴스의 프라이빗 DNS 네임과 일치해야합니다. 이 실습에서는 AWS 리소스를 연동하지 않는 구성을 가정하여 진행합니다.)
SSH 키 생성(EC2 인스턴스 환경 기준)
kubespray를 실행할 서버에서 각 노드로 접근할 SSH 키를 생성하고 생성한 키를 각 노드로 복사합니다. SSH 키의 경우 ssh-keygen 명령어로 생성하여 ssh-copy-id 명렁어로 다른 호스트에 키를 배포 가능하지만 인스턴스 생성 시 지정한 키로 접근해야하는 EC2 인스턴스 환경의 특성상 ssh-copy-id 명령어 사용이 제한적인 부분이 있습니다. 물론 모든 노드의 sshd 설정 및 패스워드 설정을 하여 ssh-copy-id 명령어를 사용해도 되지만, 더 손이 많이 가기 때문에 아래 방법으로 진행한 점 참고 부탁드립니다. kubespray를 실행할 서버에서 모든 노드의 root 계정으로 ssh 키를 이용하여 접근하도록 설정만 할 수 있다면 다른 방법으로 진행하셔도 관계없습니다.
# ssh 키 생성
ssh-keygen -b 2048 -t rsa -f ~/.ssh/id_rsa -q -N ""# 위에서 새로 생성한 ssh 키 복사를 위해 인스턴스 접속에 사용되는 키 파일 생성(EC2 인스턴스 생성 시 사용한 키)
touch ~/.ssh/premisan.pem
chmod 600 ~/.ssh/premisan.pem
vim ~/.ssh/premisan.pem
vim 상에 현재 실습에 사용할 EC2 인스턴스에 접속 가능한 키 파일의 내용을 입력합니다.
현재 노드의 키 파일을 모든 노드로 배포한 뒤, 보안상 ~/.ssh/premisan.pem 파일은 삭제합니다.
(키 유출 시 실습과 무관한 다른 인스턴스에 접근 가능성 있기 때문에)생성한 키를 각 노드로 복사(EC2 인스턴스 환경 기준)
생성한 SSH 키를 각 노드로 복사해주는 작업입니다. 위에 키 생성과 동일하게 kubespray를 실행할 서버에서 모든 노드의 root 계정으로 ssh 키를 이용하여 접근하도록 설정만 할 수 있다면 다른 방법으로 진행하셔도 관계없습니다. 참고로, SSH 키를 통해 비밀번호 없이 root 계정으로 접근이 가능해야 kubespray 를 통해 쿠버네티스 클러스터를 배포 가능하며, ~/.ssh/known_hosts 파일에 접근하려는 모든 노드의 공개키가 저장되어 있어야 정상적으로 kubespray 실행이 가능합니다. 아래 커맨드를 입력하여 키 배포 및 노드들의 공개키를 미리 등록해놓습니다.
for i in ${HOSTS}; do \
ssh-keyscan -H $(grep -w $i /etc/hosts | awk '{ print $2 }') >> ~/.ssh/known_hosts; \
cat ~/.ssh/id_rsa.pub | ssh -i ~/.ssh/premisan.pem centos@$(grep -w $i /etc/hosts | awk '{ print $2 }') \
"sudo sh -c 'cat >> /root/.ssh/authorized_keys'"; \
ssh $(grep -w $i /etc/hosts | awk '{ print $2 }') "hostname"; \
donekubespray 다운로드 및 inventory 디렉토리 복사
# 필수 패키지 설치
yum install -y python3 python3-pip wget git# kubespray 소스 클론
git clone https://github.com/kubernetes-sigs/kubespray.git# kubespray 사용을 위한 파이썬 기반 패키지 설치
cd kubespray/
pip3 install -r requirements.txt# inventory 파일 디렉토리 복사
cp -rfp inventory/sample inventory/premisan-kube# 환경 변수 세팅
HOST0_NAME=$(grep -w ${HOST0} /etc/hosts | awk '{ print $2 }')
HOST1_NAME=$(grep -w ${HOST1} /etc/hosts | awk '{ print $2 }')
HOST2_NAME=$(grep -w ${HOST2} /etc/hosts | awk '{ print $2 }')
HOST3_NAME=$(grep -w ${HOST3} /etc/hosts | awk '{ print $2 }')
HOST4_NAME=$(grep -w ${HOST4} /etc/hosts | awk '{ print $2 }')
HOST5_NAME=$(grep -w ${HOST5} /etc/hosts | awk '{ print $2 }')
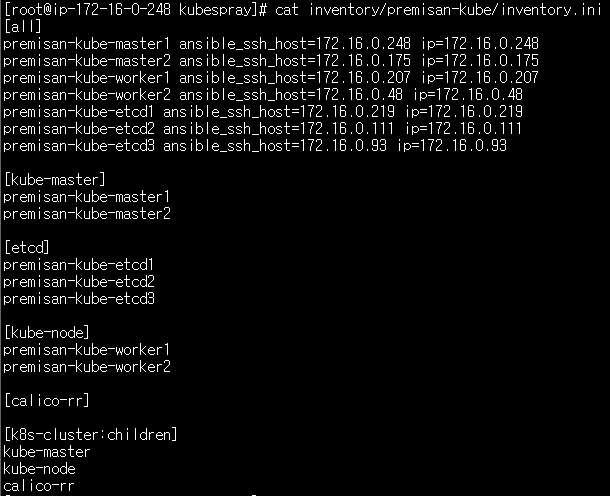
HOST6_NAME=$(grep -w ${HOST6} /etc/hosts | awk '{ print $2 }')inventory 파일 작성
여기서 inventory 파일이란 kubespary는 어플리케이션 전개/배포 도구인 ansible을 기반으로 동작하는데 ansible에서 배포할 어플리케이션에 대한 구성 파일이 inventory 파일입니다.
cat << EOF > inventory/premisan-kube/inventory.ini
[all]
${HOST0_NAME} ansible_ssh_host=${HOST0} ip=${HOST0}
${HOST1_NAME} ansible_ssh_host=${HOST1} ip=${HOST1}
${HOST2_NAME} ansible_ssh_host=${HOST2} ip=${HOST2}
${HOST3_NAME} ansible_ssh_host=${HOST3} ip=${HOST3}
${HOST4_NAME} ansible_ssh_host=${HOST4} ip=${HOST4}
${HOST5_NAME} ansible_ssh_host=${HOST5} ip=${HOST5}
${HOST6_NAME} ansible_ssh_host=${HOST6} ip=${HOST6}
[kube-master]
${HOST0_NAME}
${HOST1_NAME}
[etcd]
${HOST4_NAME}
${HOST5_NAME}
${HOST6_NAME}
[kube-node]
${HOST2_NAME}
${HOST3_NAME}
[calico-rr]
[k8s-cluster:children]
kube-master
kube-node
calico-rr
EOF위의 커맨드로 inventory 파일 작성 시 아래와 같이 결과가 나오면 됩니다. 굳이 환경변수 설정 안하고 수동으로 일일이 작성해도 관계 없습니다. 우리가 구성할 쿠버네티스 클러스터의 구성(마스터노드 2개, 워커노드 2개, etcd 노드 3개)을 상기하시면서 아래 이미지를 참고 부탁드립니다.
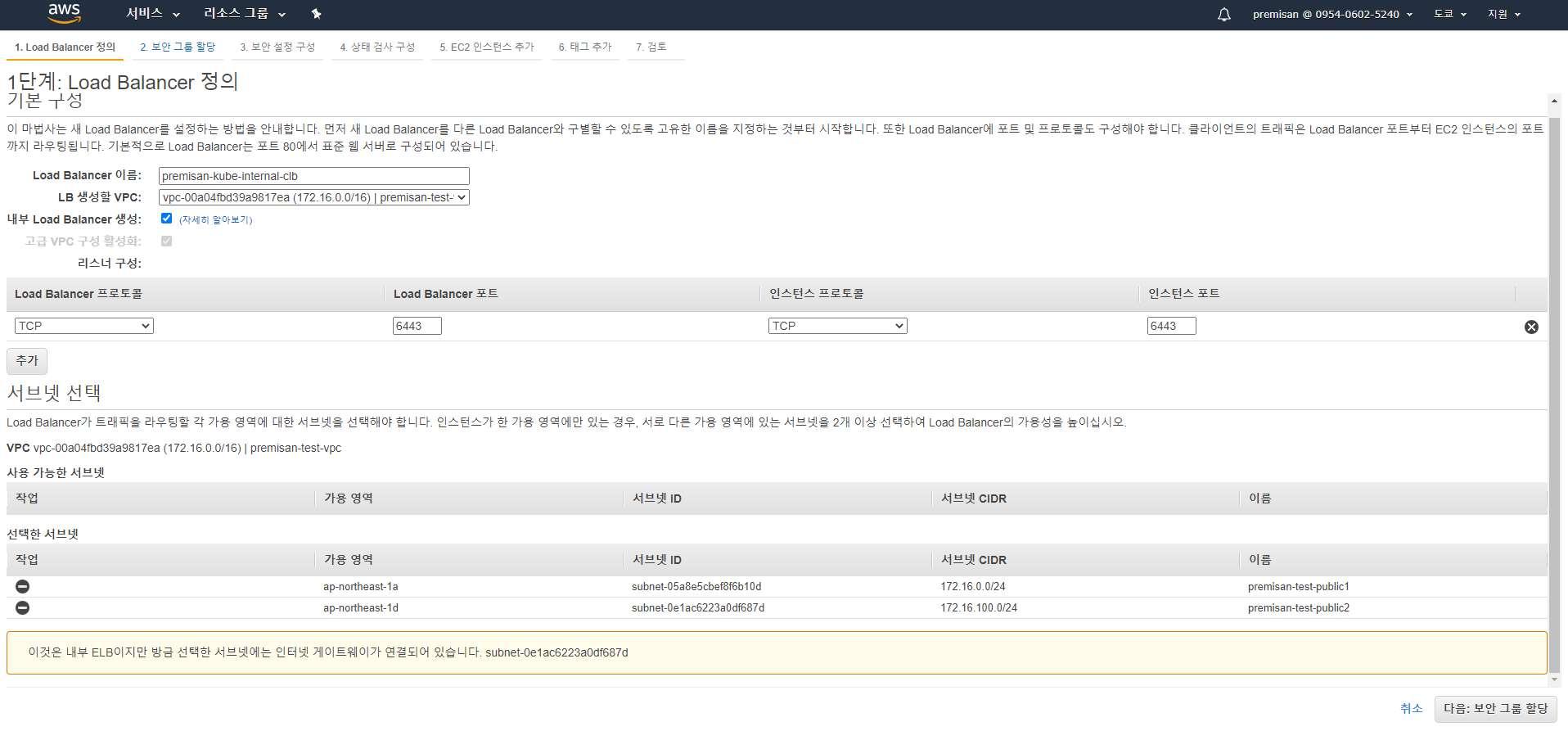
다중 마스터노드 환경을 위한 외부 로드밸런서 생성
우리가 구성할 쿠버네티스 클러스터는 마스터노드(kube-apiserver)가 2개 이상이기 때문에 로드밸런서를 통해 api 통신을 로드밸런싱합니다. 클래식 로드 밸런서를 내부 로드밸런서 타입으로 생성했습니다. 리스닝 포트 및 VPC 설정 반드시 확인하시고 생성하시기 바랍니다.
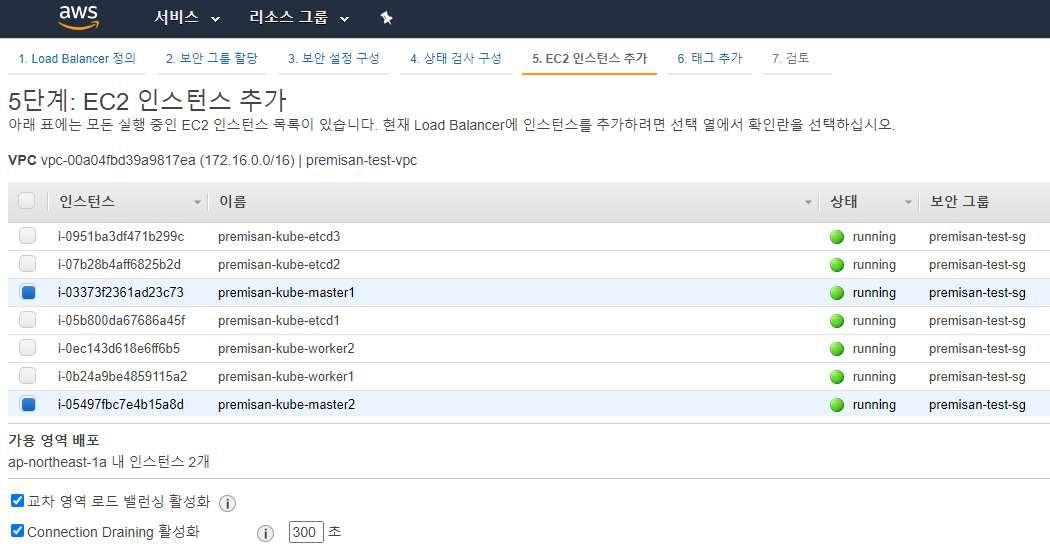
보안그룹 설정은 EC2 인스턴스와 동일한 보안그룹으로 하셔도 되며, 디테일하게 설정하고 싶으신 분은 kube-apiserver 통신을 위한 6443포트에 유의하여 커스텀하셔도 됩니다. 인스턴스 추가 단계에서는 마스터노드 2개만 포함시킵니다.
다중 마스터 노드를 위한 inventory 설정 파일 수정
~/kubespray/inventory/premisan-kube/group_vars/all/all.yml 파일의 apiserver_loadbalancer_domain_name 옵션을 주석해제 후 생성한 로드밸런서의 도메인을 입력합니다.(밑에 있는 address, port 부분은 그대로 주석으로 둡니다)
vim inventory/premisan-kube/group_vars/all/all.yml
## External LB example config
apiserver_loadbalancer_domain_name: "internal-premisan-kube-internal-clb-142660259.ap-northeast-1.elb.amazonaws.com"
# loadbalancer_apiserver:
# address: 1.2.3.4
# port: 1234(옵션) 클러스터 배포 시 추가적으로 설치할 애드온 설정
기본적으로 kubespray로 쿠버네티스 배포 시 네트워크 애드온인 calico과 쿠버네티스 대시보드가 포함되어 배포됩니다. 추가적으로 설치하고자하는 애드온이 있다면 아래 경로에서 필요에 따라 주석해제 혹은 true로 설정하여 배포할 애드온을 구성합니다.
vim inventory/premisan-kube/group_vars/k8s-cluster/addons.yml
(아래는 노드 및 포드의 리소스 사용량을 수집하는 metrics-server 애드온을 활성화시키는 예시입니다. 필수적인 부분은 아닙니다)
metrics_server_enabled: false -> true 변경클러스터 배포 실행
이제 구성한 inventory 파일과 ansible-playbook 명령어를 이용하여 쿠버네티스 클러스터를 배포합니다.
ansible-playbook --flush-cache -u root -b -i inventory/premisan-kube/inventory.ini cluster.yml
(참고)
-b(--become) 옵션이 포함되어야 root가 아닌 유저가 배포를 실행하는 경우에도 권한 문제가 발생하지 않음,
-u(--user) REMOTE_USER 옵션으로 대상 노드의 root 유저로 접속하여 배포 수행,
--flush-cache 옵션은 인벤토리의 모든 호스트에 대한 캐쉬 클리어클러스터 배포 확인
kubespray를 통해 쿠버네티스 클러스터가 배포되는대에 약 10~15분 정도 소요됩니다.(7개의 노드로 클러스터를 배포하였을 경우 클러스터 배포 완료까지 11분이 걸렸습니다) 아래와 같이 완료되었다는 출력이 확인되면 노드를 확인해봅니다.
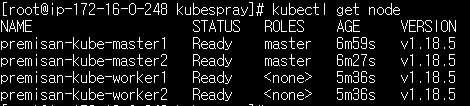
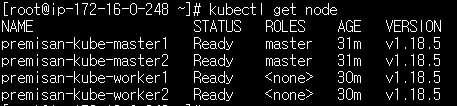
kubectl get node(etcd 노드는 노드 목록에 안보이는게 정상입니다)
위의 내용까지 완료하였다면 쿠버네티스 클러스터의 배포는 완료되었습니다. 아래부터는 테스트 배포 및 접속 테스트를 위한 인그레스 배포가 포함되어 있습니다.
helm(쿠버네티스 패키지 매니저) 설치
nginx-ingress 배포를 위해 쿠버네티스 패키지 매니저인 helm을 설치합니다.
## 설치
curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get > get_helm.sh
chmod +x get_helm.sh
./get_helm.sh
## tiller 계정 생성(클러스터의 리소스 관리)
cat <<EoF > ~/rbac.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
EoF
kubectl apply -f ~/rbac.yaml
helm init --service-account tiller
## 레포 업데이트
helm repo updatenginx-ingress 배포
nginx-ingress는 deployment 타입과 daemonset 타입을 선택하여 설치할 수 있습니다. 퍼블릭 클라우드의 로드밸런서를 연동하지 않고 워커노드의 80 포트로 접속 테스트를 해보려면 아래와 같이 옵션을 세팅하여 nginx-ingress를 배포합니다. (다른 옵션도 있지만 설명이 너무 길어져 기재하지는 않겠습니다)
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx/
helm install --name ingress-nginx --namespace ingress-nginx ingress-nginx/ingress-nginx \
--set controller.kind=DaemonSet,controller.service.type=ClusterIP,controller.hostNetwork=true
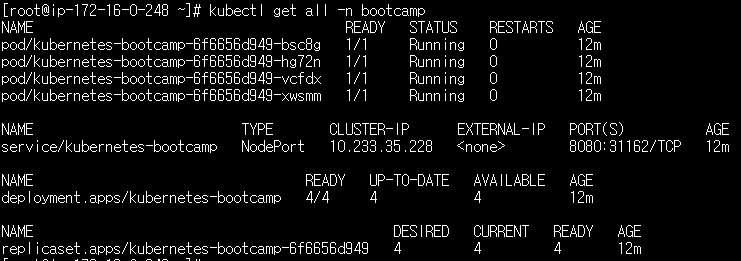
kubectl get all -n ingress-nginx테스트 배포 생성
# 네임스페이스 생성
kubectl create ns bootcamp
# 배포 생성
kubectl create deployment kubernetes-bootcamp --image=gcr.io/google-samples/kubernetes-bootcamp:v1 -n bootcamp
# 배포를 노출(서비스 오브젝트 생성)
kubectl expose deployment kubernetes-bootcamp --port=8080 --type=NodePort --name=kubernetes-bootcamp -n bootcamp
# 포드 스케일 아웃
kubectl scale deploy kubernetes-bootcamp --replicas=4 -n bootcamp
# 인그레스 생성
cat << EOF > bootcamp-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: bootcamp-ingress
namespace: bootcamp
annotations:
ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host:
http:
paths:
- path: /
backend:
serviceName: kubernetes-bootcamp
servicePort: 8080
EOF
kubectl apply -f bootcamp-ingress.yaml접속 테스트
워커노드1, 2의 공인 아이피 둘 중 아무거나 브라우저에 입력하여 접속해봅니다.
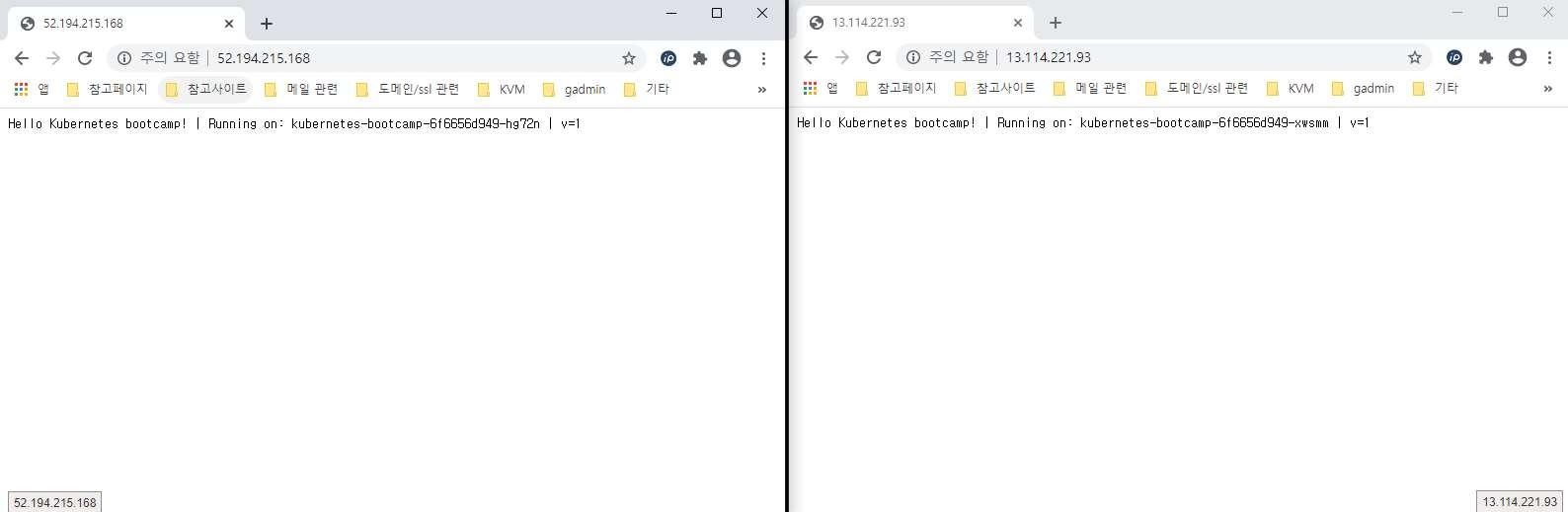
여기까지 테스트 배포 생성 및 접속 테스트 완료되었습니다. 아래부터는 장애 발생 상황을 가정하여 테스트를 진행합니다.
마스터노드(kube-apiserver) HA 테스트
마스터노드는 현재 2개로 구성되어 있으며, AWS internal CLB를 통해 트래픽을 분산하고 있습니다. 마스터노드 중 1개를 다운시켜 장애 상황을 가정하고 고가용성이 유지되는지 확인해봅니다.
노드 중 master2 노드를 다운시킵니다.
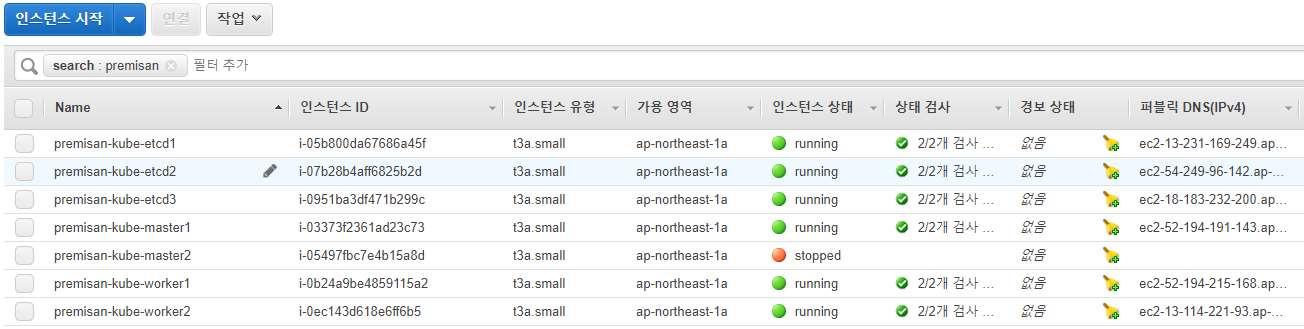
master2 노드가 다운된 것이 확인됩니다.
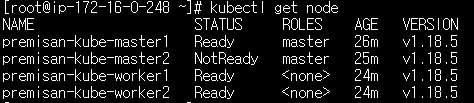
로드밸런서가 마스터노드 2개의 6443 포트를 상태검사하여 다운된 마스터노드로는 트래픽을 보내지 않게 됩니다.
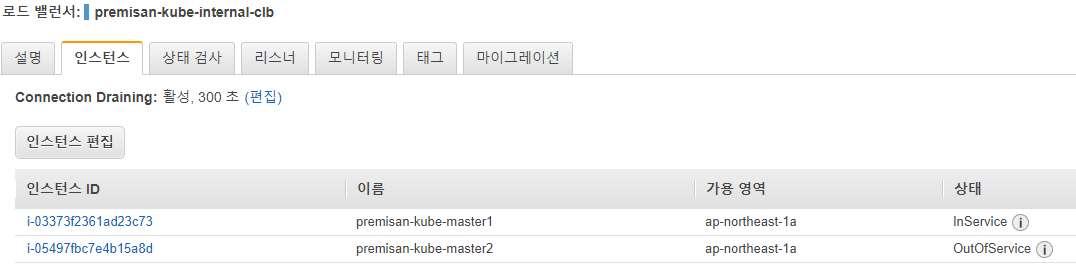
kubectl 명령어를 통해 클러스터와 통신이 계속 가능하다면 HA 구성이 정상적이라고 생각할 수 있습니다.
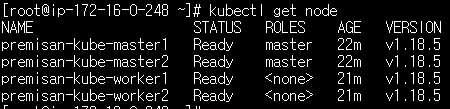
HA 확인이 완료되었다면 다시 마스터노드2 인스턴스를 실행시켜 다시 클러스터의 모든 노드가 정상 상태인지 확인합니다.
etcd 노드 HA 테스트
먼저 정상 상태의 etcd 노드에는 etcd 컨테이너가 실행 중인 것을 확인할 수 있습니다.
(etcd 노드 중 아무 노드에서나 실행)
docker ps -a
마스터노드에서 etcd 클러스터 상태 확인을 위한 커맨드를 생성합니다.
# 호스트 4/5/6은 etcd 노드이며, 아이피주소는 각자 환경에 맞게 수정합니다.
export HOST4=172.16.0.219
export HOST5=172.16.0.111
export HOST6=172.16.0.93
K8S_VERSION=`kubelet --version | awk -Fv '{ print $2 }'`
ETCD_TAG=`kubeadm config images list --kubernetes-version ${K8S_VERSION} | grep etcd | awk -F: '{ print $2 }' | awk -F- '{ print $1 }'`
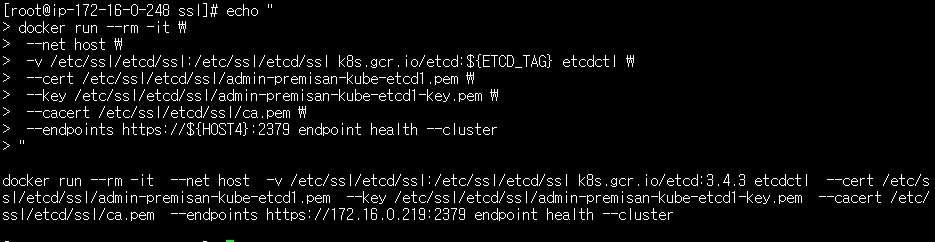
# 인증서 파일 경로의 "premisan-kube-etcd1"는 제가 구성한 etcd 노드의 호스트명입니다. 각자 구성한 환경에 맞게 수정합니다.
echo "
docker run --rm -it \\
--net host \\
-v /etc/ssl/etcd/ssl:/etc/ssl/etcd/ssl k8s.gcr.io/etcd:${ETCD_TAG} etcdctl \\
--cert /etc/ssl/etcd/ssl/admin-premisan-kube-etcd1.pem \\
--key /etc/ssl/etcd/ssl/admin-premisan-kube-etcd1-key.pem \\
--cacert /etc/ssl/etcd/ssl/ca.pem \\
--endpoints https://${HOST4}:2379 endpoint health --cluster
"etcd 클러스터 상태 확인용 커맨드를 만들었습니다. 출력된 커맨드를 복사합니다.
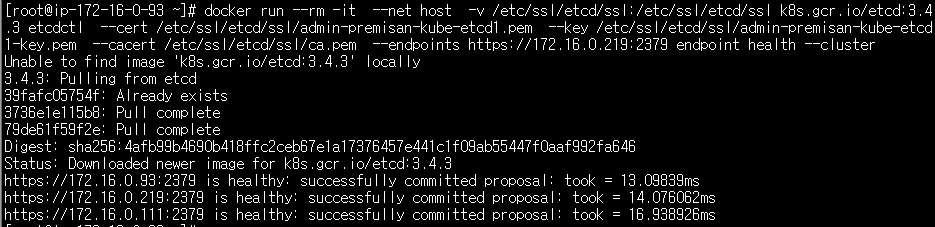
etcd 노드 중 아무노드로 이동하여 복사한 커맨드를 실행합니다. 환경에 따라 아이피주소 및 인증서 파일 경로, etcd 이미지 버전 등이 다르니 반드시 확인 후 실행합니다.
docker run --rm -it --net host -v /etc/ssl/etcd/ssl:/etc/ssl/etcd/ssl k8s.gcr.io/etcd:3.4.3 etcdctl \
--cert /etc/ssl/etcd/ssl/admin-premisan-kube-etcd1.pem \
--key /etc/ssl/etcd/ssl/admin-premisan-kube-etcd1-key.pem \
--cacert /etc/ssl/etcd/ssl/ca.pem \
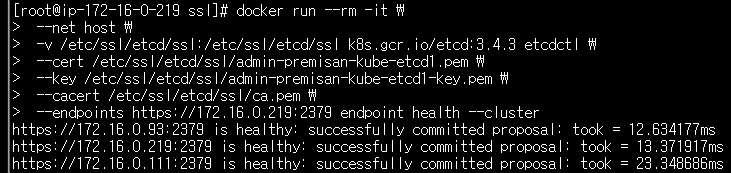
--endpoints https://172.16.0.219:2379 endpoint health --clusteretcd 클러스터의 상태가 모두 healthy 로 확인됩니다.
etcd 클러스터 중 하나의 노드를 다운시킵니다. 저는 etcd2 노드(HOST5)를 다운시켰습니다.
전 단계에서 실행했던 헬스 체크 명령어를 다시 실행해봅니다. 172.16.0.111(HOST5) etcd 노드가 unhealthy 상태로 확인됩니다.
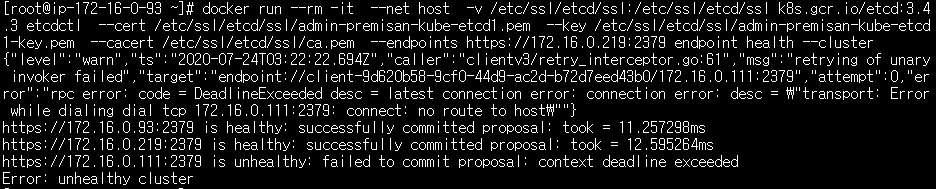
etcd HA가 정상적으로 작동하고 있는지 마스터노드에서 kubectl 명령어로 리소스를 조회해봅니다. etcd 클러스터의 모든 노드가 정상적으로 작동하지 않는다면 etcd 에 저장된 쿠버네티스 클러스터의 리소스를 불러오지 못해 명령어 실행이 실패합니다.
etcd 클러스터의 1개 노드가 다운되었지만 다른 etcd 노드를 통해 쿠버네티스 리소스들을 정상적으로 불러오는 것을 확인할 수 있습니다. 테스트가 완료되면 중지시켰던 etcd 노드 인스턴스를 다시 시작하여 헬스 체크가 정상적인지 확인해봅니다. 모든 etcd 노드가 정상적인 것을 확인할 수 있습니다.
워커노드 HA 테스트
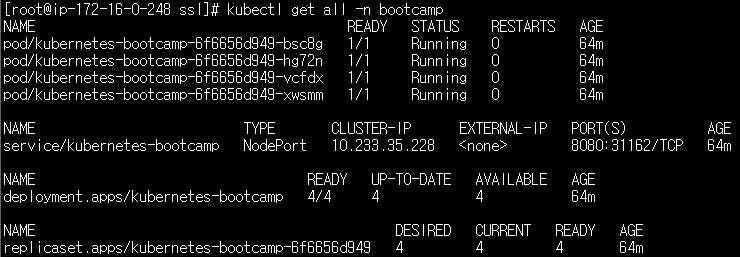
마지막으로 워커노드의 HA 테스트를 진행합니다. 먼저 현재 배포된 포드들의 상태를 확인합니다.
kubectl get pod -n bootcamp -o wide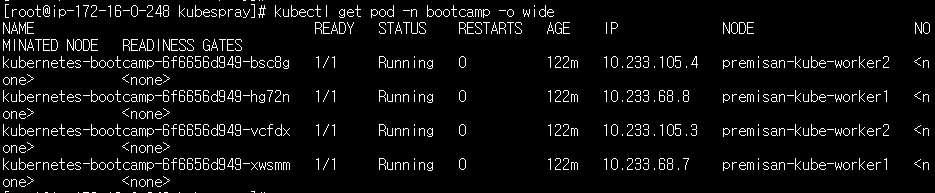
NODE 부분을 보시면 워커노드1과 워커노드 2에 포드가 고르게 분산되어 있는 것을 확인할 수 있습니다. 이제 워커노드 중 하나를 다운시킵니다. 전 워커노드1을 다운시켰습니다. 노드의 상태를 체크하는 kube-controller-manager에서 응답이 없는 노드에 대해 비정상 상태로 전환하는 설정인 node-monitor-grace-period 옵션값의 기본값은 40초로 설정되어 있기 때문에 40초가 경과하면 아래와 같이 워커노드1의 STATUS가 "NotReady" 상태로 전환됩니다.
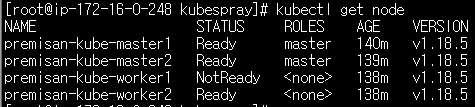
하지만 포드의 상태를 다시 확인하여도 아무런 변화가 없는 것을 확인할 수 있습니다.
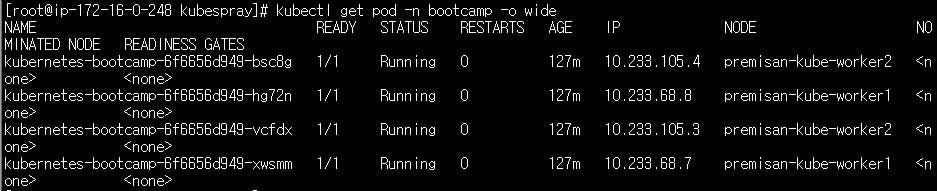
그 이유는 비정상 노드에 배치된 포드를 다른 노드로 축출하는 kube-controller-manager의 옵션인 pod-eviction-timeout 의 기본값이 5분이기 때문입니다. 해당 설정값은 클러스터 최초 배포 시 설정이 가능합니다. 우리는 kube-controller-manager의 옵션을 별도로 커스텀하지 않았기 때문에 기본값인 5분이 적용될 것입니다. 비정상 노드로부터 정상 노드로 포드가 축출되도록 포드의 상태를 계속해서 지켜봅니다.
watch kubectl get pod -n bootcamp -o wide워커노드 다운으로부터 5분이 지나면 아래와 같이 워커노드1에 배치되어 있던 포드가 모두 워커노드2에 새로 생성된 것을 확인할 수 있습니다.
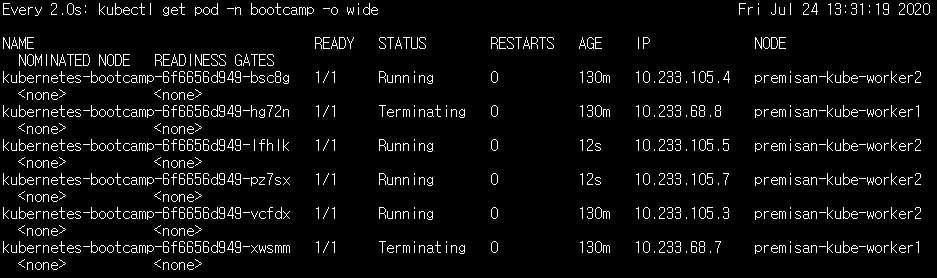
만약 워커노드 다운 시 더 빠르게 정상 노드에서 새 포드를 생성하도록 하려면 클러스터 초기 구성 시 pod-eviction-timeout 옵션 값을 기본값인 5분보다 더 짧게 세팅하면 되겠습니다. 해당 설정값은 ~/kubespray/roles/kubernetes/master/defaults/main/main.yml 파일에 아래와 같이 기본값으로 설정되어 있는 것을 확인할 수 있습니다.
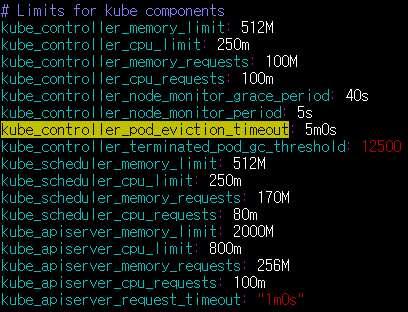
여기까지 쿠버네티스의 HA 구성 방법 2가지(stacked etcd, external etcd)와 kubespray를 통해 HA 구성이 포함된 쿠버네티스 클러스터를 배포하는 방법을 알아보았습니다.